Effects of compression techniques on data read/write performance
1 Post summary
Following our previous exploration of data read/write performance, we now delve into the effects of different compression techniques on these processes. Compression is vital for optimizing storage efficiency and access speed. This post covers the definitions of compression methods, factors influencing compression efficiency, guidelines for using higher or lower compression, and detailed empirical testing results.
2 Purpose and Motivation
Compression is essential for reducing storage requirements and improving data access times. By understanding the impact of different compression techniques, we can optimize data handling in R, making it more efficient and effective. This study explores various compression methods to provide insights into their performance in different scenarios.
3 Detailed Overview of Compression Techniques
Understanding the specific characteristics and use cases of various compression techniques is crucial for optimizing data storage and access. Below, we delve deeper into the most commonly used compression methods, detailing their strengths, weaknesses, and ideal applications.
3.1 Gzip (GNU zip)
Gzip uses the DEFLATE algorithm, which balances speed and compression ratio. It is widely supported across different platforms and programming languages, making it effective for both text and binary data. Its primary strength lies in providing a good compromise between compression speed and ratio, making it a popular choice for general-purpose compression. However, Gzip is not the fastest in terms of compression or decompression speeds, and its compression ratios are moderate compared to newer algorithms. It is ideal for general-purpose compression where compatibility and ease of use are important, such as web servers for compressing HTTP responses and archiving files where space saving is needed but not critical.
3.2 Snappy
Snappy is optimized for speed, making it ideal for applications requiring rapid read/write operations. It excels in scenarios where quick compression and decompression are more critical than achieving the highest compression ratio. Snappy’s primary strength is its high speed, both in compression and decompression, which minimizes latency in data processing. However, this comes at the cost of lower compression ratios compared to other algorithms. Snappy is best suited for real-time data processing, log compression, and systems where performance is a higher priority than storage efficiency.
3.3 Zstandard (Zstd)
Zstandard, or Zstd, offers high compression ratios and fast decompression, making it excellent for scenarios that need high compression without significant speed loss. Zstd is highly versatile, providing various compression levels to balance speed and compression ratio according to the application’s needs. Its strengths include superior compression ratios and efficient decompression speeds, often outperforming older algorithms like Gzip. One downside is that higher compression levels can be resource-intensive in terms of CPU and memory usage. Zstd is ideal for large-scale data storage, backup solutions, and systems where both speed and storage efficiency are critical.
3.4 Brotli
Brotli achieves high compression ratios, especially for text data, making it perfect for web content. Developed by Google, Brotli provides excellent compression efficiency for web fonts and other web assets, significantly reducing file sizes and improving load times. Its primary strength lies in its ability to achieve superior compression ratios for text data, which is crucial for optimizing web performance. However, Brotli can be slower than other algorithms in both compression and decompression, particularly at higher compression levels. Brotli is best used for web content delivery, where minimizing bandwidth usage and improving load times are paramount.
3.5 LZ4
LZ4 prioritizes speed over compression ratio, making it ideal for real-time data processing. It is designed to provide extremely fast compression and decompression, which is critical in performance-sensitive environments. LZ4’s strengths include its lightning-fast speeds, which make it suitable for scenarios where data needs to be processed in real-time. However, its compression ratios are lower than those of more advanced algorithms like Zstd or Brotli. LZ4 is particularly useful for in-memory compression, real-time logging, and applications where speed is more important than achieving the highest compression ratio.
3.6 Uncompressed
Storing data in its original format without compression ensures the fastest possible read and write speeds, as there is no overhead from compression or decompression processes. This approach is best when speed is crucial, and storage space is not a concern. The primary advantage of uncompressed data is the elimination of latency related to compression algorithms, providing immediate access to data. However, the downside is the significantly larger storage requirement. Uncompressed storage is ideal for applications where performance is paramount and storage costs are negligible, such as temporary data storage and real-time data analytics.
By understanding these compression techniques’ specific advantages and limitations, you can make informed decisions to optimize data storage and access for various applications.
4 Factors influencing compression efficiency
Several critical factors influence the efficiency of compression techniques, determining their suitability for different scenarios.
Data type and structure play a significant role in compression efficiency. Text data typically compresses well with algorithms like Brotli, which are designed to handle repetitive patterns in text efficiently. Conversely, numerical data often benefits more from algorithms like Zstandard (Zstd), which can provide higher compression ratios for such data types due to its sophisticated encoding mechanisms.
Compression levels are another crucial factor. Higher compression levels generally increase the compression ratio, resulting in smaller file sizes. However, this improvement comes at the cost of reduced speed and increased CPU and memory resource requirements. Therefore, selecting an appropriate compression level involves balancing the need for smaller file sizes against the available computational resources and required processing speeds.
CPU and memory capabilities of the hardware significantly impact compression and decompression speeds. Devices with higher processing power and more available memory can handle more intensive compression tasks more efficiently. In contrast, limited resources can bottleneck the performance, making it essential to choose a compression method that aligns with the hardware’s capabilities.
Application needs also dictate the choice of compression technique. Real-time processing environments demand speed, necessitating the use of algorithms optimized for quick compression and decompression, such as Snappy or LZ4. On the other hand, archival purposes benefit from higher compression ratios to minimize storage space, making algorithms like Brotli or Zstd more suitable due to their superior compression efficiency.
Understanding these factors allows for a more informed selection of compression techniques, optimizing performance and efficiency according to specific data handling requirements and resource constraints.
5 Database Structure and Compression
The structure of the database plays a crucial role in determining the efficiency of compression. For this study, we use a generated dataset that simulates real-world data complexity, enabling a comprehensive assessment of various compression techniques on read/write performance.
5.1 Device specifications
13th‑Gen Intel Core i7‑13620H 32 GB RAM - Windows 64‑bit
5.2 Dataset generation
We benchmark row counts 10^6, and three structures (numeric, character, mixed). The helper below fabricates a mixed‑type frame:
knitr::opts_chunk$set(echo = TRUE, cache = TRUE)
source("utils.R")## Warning: package 'tidyverse' was built under R version 4.4.3## Warning: package 'ggplot2' was built under R version 4.4.3## Warning: package 'tibble' was built under R version 4.4.3## Warning: package 'readr' was built under R version 4.4.1## Warning: package 'purrr' was built under R version 4.4.3## Warning: package 'stringr' was built under R version 4.4.3## Warning: package 'forcats' was built under R version 4.4.3## Warning: package 'lubridate' was built under R version 4.4.3## Warning: package 'data.table' was built under R version 4.4.3## Warning: package 'arrow' was built under R version 4.4.3## Warning: package 'qs' was built under R version 4.4.3## Warning: package 'fst' was built under R version 4.4.1## Warning: package 'microbenchmark' was built under R version 4.4.3generate_sample_data <- function(n, type = "mixed"){
set.seed(123)
if(type == "numeric"){
data.frame(ID = seq_len(n), Value = rnorm(n))
} else if(type == "character"){
data.frame(ID = seq_len(n),
Description = replicate(n, paste0(sample(letters,20,TRUE),
collapse="")))
} else {
data.frame(
ID = seq_len(n),
Value = rnorm(n),
Category = sample(letters[1:5], n, TRUE),
Description = replicate(n, paste0(sample(letters,20,TRUE), collapse=""))
)
}
}
sample_size <- 1e6
dt_list <- list(
numeric = as.data.table(generate_sample_data(sample_size, "numeric")),
character = as.data.table(generate_sample_data(sample_size, "character")),
mixed = as.data.table(generate_sample_data(sample_size, "mixed"))
)6 I/O function lists
## I/O function lists
write_funcs <- list(
parquet_gzip =
function(d,f) arrow::write_parquet(d, f, compression = "gzip"),
parquet_snappy =
function(d,f) arrow::write_parquet(d, f, compression = "snappy"),
parquet_zstd =
function(d,f) arrow::write_parquet(d, f, compression = "zstd"),
parquet_uncompressed =
function(d,f) arrow::write_parquet(d, f, compression = "uncompressed"),
qs_fast =
function(d,f) qs::qsave(d, f, preset = "fast"),
fst_uncompressed =
function(d,f) fst::write_fst(d, f, compress = 0),
dt_gzip =
function(d,f) data.table::fwrite(d, f, compress = "gzip"),
dt_none =
function(d,f) data.table::fwrite(d, f, compress = "none")
)
read_funcs <- list(
parquet_gzip = function(f) arrow::read_parquet(f),
parquet_snappy = function(f) arrow::read_parquet(f),
parquet_zstd = function(f) arrow::read_parquet(f),
parquet_uncompressed = function(f) arrow::read_parquet(f),
qs_fast = function(f) qs::qread(f),
fst_uncompressed = function(f) fst::read_fst(f),
dt_gzip = function(f) data.table::fread(f),
dt_none = function(f) data.table::fread(f)
)7 Results
results <- lapply(names(dt_list), function(structure) {
paths <- get_paths(structure)
out <- run_benchmarks_one(dt_list[[structure]], paths, write_funcs,
read_funcs)
out$write_summary$structure <- structure
out$read_summary$structure <- structure
out$size_summary$structure <- structure
out
})
write_summary_all <- dplyr::bind_rows(lapply(results, `[[`, "write_summary"))
read_summary_all <- dplyr::bind_rows(lapply(results, `[[`, "read_summary"))
size_summary_all <- dplyr::bind_rows(lapply(results, `[[`, "size_summary"))7.1 Summarising
pretty_method <- c(
fst_uncompressed = "fst (uncompressed)",
qs_fast = "qs (preset = 'fast')",
parquet_snappy = "Parquet + Snappy",
parquet_zstd = "Parquet + Zstd",
parquet_uncompressed = "Parquet (uncompressed)",
parquet_gzip = "Parquet + Gzip",
dt_none = "CSV via data.table (none)",
dt_gzip = "CSV via data.table (gzip)"
)
write_s <- write_summary_all %>%
dplyr::mutate(method = method_from_expr(expr)) %>%
select(structure, method,
write_median_ms = median,
write_mean_ms = mean,
write_sd_ms = sd)
read_s <- read_summary_all %>%
dplyr::mutate(method = method_from_expr(expr)) %>%
select(structure, method,
read_median_ms = median,
read_mean_ms = mean,
read_sd_ms = sd)
cons <- write_s %>%
inner_join(read_s, by = c("structure","method")) %>%
left_join(size_summary_all %>%
select(structure, method, size_MB, relative_size),
by = c("structure","method")) %>%
dplyr::mutate(Method = recode(method, !!!pretty_method)) %>%
arrange(structure, write_median_ms)
unique(cons$structure) %>%
walk(~ print_per_structure(cons, .x))
write_wide <- cons %>%
select(structure, Method, `Write (ms)` = write_median_ms) %>%
pivot_wider(names_from = structure, values_from = `Write (ms)`) %>%
arrange(`mixed`) # or order by 'numeric' etc.
knitr::kable(write_wide, digits = 1,
caption = "Median write time (ms) by storage method and data structure")| Method | character | mixed | numeric |
|---|---|---|---|
| CSV via data.table (none) | 41.2 | 61.1 | 28.6 |
| fst (uncompressed) | 44.7 | 67.3 | 8.1 |
| qs (preset = ‘fast’) | 62.2 | 107.1 | 11.9 |
| Parquet (uncompressed) | 127.1 | 203.5 | 47.9 |
| Parquet + Snappy | 191.2 | 261.6 | 48.5 |
| Parquet + Zstd | 216.0 | 292.2 | 73.1 |
| CSV via data.table (gzip) | 212.0 | 331.2 | 270.8 |
| Parquet + Gzip | 2134.4 | 2461.4 | 829.0 |
# Wide table: read medians
read_wide <- cons %>%
select(structure, Method, `Read (ms)` = read_median_ms) %>%
pivot_wider(names_from = structure, values_from = `Read (ms)`) %>%
arrange(`mixed`)
knitr::kable(read_wide, digits = 1,
caption = "Median read time (ms) by storage method and data structure")| Method | character | mixed | numeric |
|---|---|---|---|
| Parquet (uncompressed) | 61.6 | 80.8 | 28.2 |
| Parquet + Snappy | 76.4 | 91.7 | 28.8 |
| Parquet + Zstd | 87.5 | 110.8 | 45.1 |
| Parquet + Gzip | 228.6 | 338.3 | 93.7 |
| fst (uncompressed) | 288.7 | 443.4 | 6.2 |
| qs (preset = ‘fast’) | 306.9 | 464.1 | 15.8 |
| CSV via data.table (none) | 336.8 | 491.1 | 16.9 |
| CSV via data.table (gzip) | 846.8 | 1169.3 | 440.3 |
# Wide table: sizes
size_wide <- cons %>%
select(structure, Method, `Size (MB)` = size_MB) %>%
pivot_wider(names_from = structure, values_from = `Size (MB)`)
knitr::kable(size_wide, digits = 2,
caption = "File size (MB) by method and structure")| Method | character | mixed | numeric |
|---|---|---|---|
| CSV via data.table (none) | 27.55 | 46.78 | 24.84 |
| fst (uncompressed) | 26.83 | 39.35 | 11.44 |
| qs (preset = ‘fast’) | 23.94 | 32.49 | 11.49 |
| Parquet (uncompressed) | 27.35 | 35.61 | 12.28 |
| Parquet + Snappy | 25.28 | 33.54 | 12.28 |
| CSV via data.table (gzip) | 15.80 | 26.64 | 10.53 |
| Parquet + Zstd | 15.46 | 23.35 | 10.67 |
| Parquet + Gzip | 15.30 | 23.19 | 9.41 |
method_from_expr <- function(expr) sub("^write_|^read_", "", expr)
# Prepare write and read with ratios
write_s <- write_summary_all %>%
mutate(method = method_from_expr(expr)) %>%
select(structure, method, write_median_ms = median) %>%
normalise_ratio("write_median_ms")
read_s <- read_summary_all %>%
mutate(method = method_from_expr(expr)) %>%
select(structure, method, read_median_ms = median) %>%
normalise_ratio("read_median_ms")
# Prepare sizes with ratio to smallest
size_s <- size_summary_all %>%
normalise_ratio("size_MB") %>%
select(structure, method, size_MB, size_MB_ratio)
# Join all
consolidated_ratio <- write_s %>%
inner_join(read_s, by = c("structure", "method")) %>%
left_join(size_s, by = c("structure", "method")) %>%
mutate(Method = recode(method, !!!pretty_method)) %>%
arrange(structure, write_median_ms)
knitr::kable(
consolidated_ratio %>%
select(structure, Method,
`Write (ms)` = write_median_ms,
`Write (×)` = write_median_ms_ratio,
`Read (ms)` = read_median_ms,
`Read (×)` = read_median_ms_ratio,
`Size (MB)` = size_MB,
`Size (×)` = size_MB_ratio),
digits = 2,
caption = "Median write/read times and file size with ratios (from fastest/smallest) by method and structure"
)| structure | Method | Write (ms) | Write (×) | Read (ms) | Read (×) | Size (MB) | Size (×) |
|---|---|---|---|---|---|---|---|
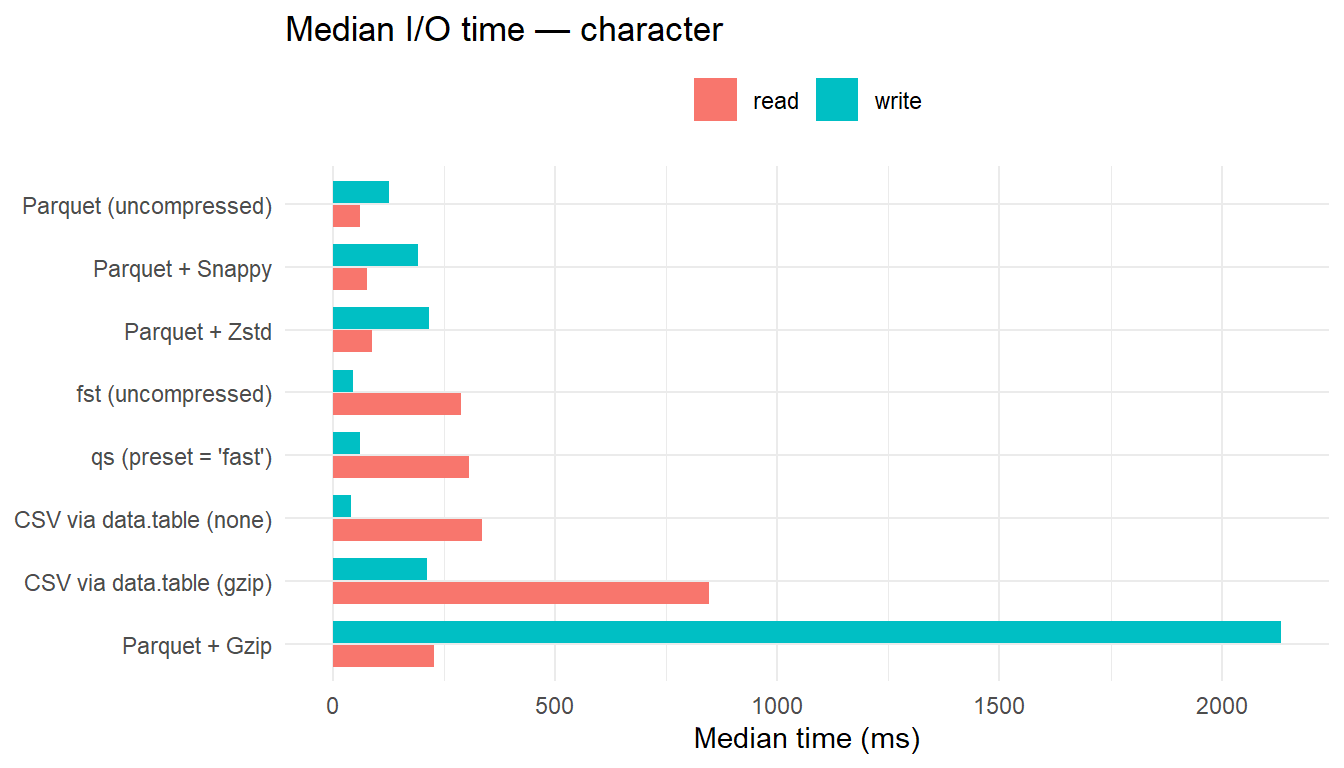
| character | CSV via data.table (none) | 41.22 | 1.00 | 336.81 | 5.46 | 27.55 | 1.80 |
| character | fst (uncompressed) | 44.67 | 1.08 | 288.73 | 4.68 | 26.83 | 1.75 |
| character | qs (preset = ‘fast’) | 62.17 | 1.51 | 306.94 | 4.98 | 23.94 | 1.56 |
| character | Parquet (uncompressed) | 127.14 | 3.08 | 61.63 | 1.00 | 27.35 | 1.79 |
| character | Parquet + Snappy | 191.23 | 4.64 | 76.40 | 1.24 | 25.28 | 1.65 |
| character | CSV via data.table (gzip) | 211.96 | 5.14 | 846.76 | 13.74 | 15.80 | 1.03 |
| character | Parquet + Zstd | 216.01 | 5.24 | 87.53 | 1.42 | 15.46 | 1.01 |
| character | Parquet + Gzip | 2134.44 | 51.79 | 228.64 | 3.71 | 15.30 | 1.00 |
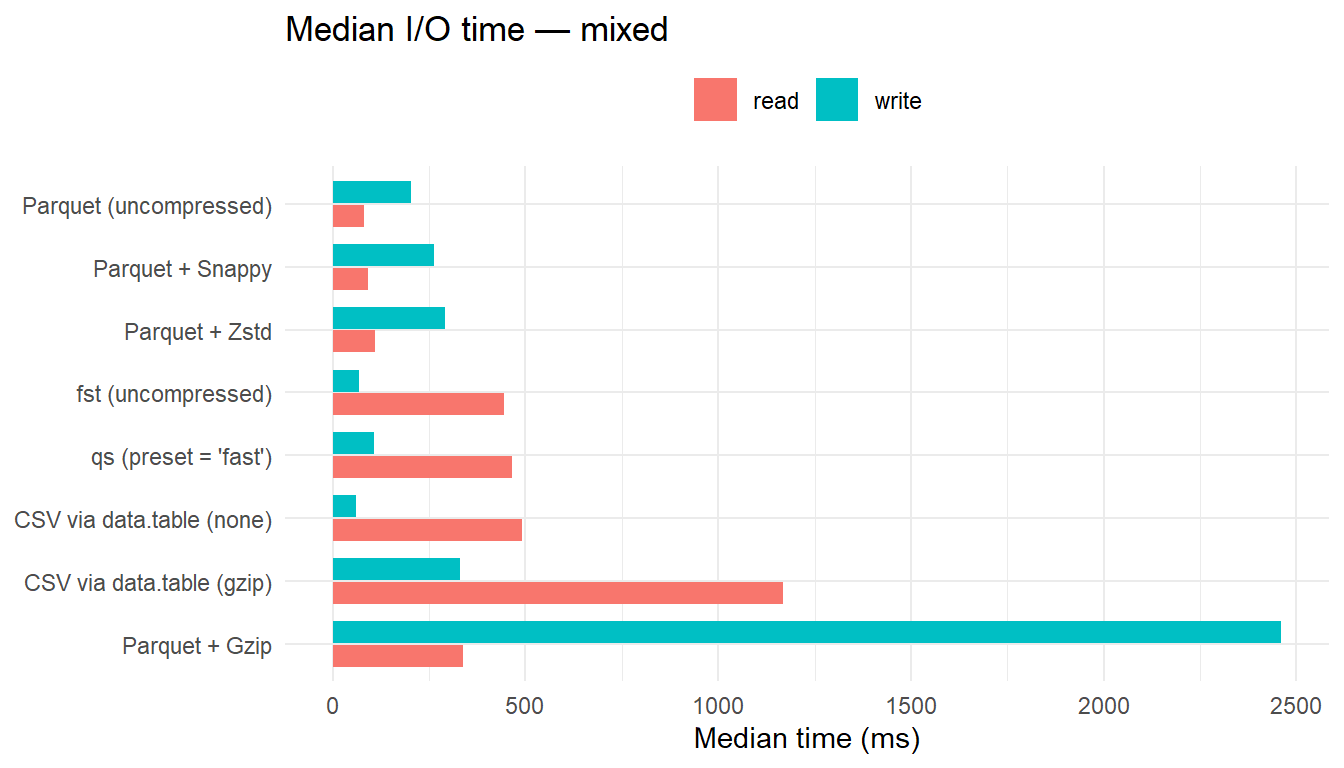
| mixed | CSV via data.table (none) | 61.15 | 1.00 | 491.09 | 6.08 | 46.78 | 2.02 |
| mixed | fst (uncompressed) | 67.34 | 1.10 | 443.37 | 5.49 | 39.35 | 1.70 |
| mixed | qs (preset = ‘fast’) | 107.14 | 1.75 | 464.14 | 5.75 | 32.49 | 1.40 |
| mixed | Parquet (uncompressed) | 203.47 | 3.33 | 80.78 | 1.00 | 35.61 | 1.54 |
| mixed | Parquet + Snappy | 261.62 | 4.28 | 91.66 | 1.13 | 33.54 | 1.45 |
| mixed | Parquet + Zstd | 292.15 | 4.78 | 110.82 | 1.37 | 23.35 | 1.01 |
| mixed | CSV via data.table (gzip) | 331.21 | 5.42 | 1169.32 | 14.47 | 26.64 | 1.15 |
| mixed | Parquet + Gzip | 2461.44 | 40.26 | 338.26 | 4.19 | 23.19 | 1.00 |
| numeric | fst (uncompressed) | 8.06 | 1.00 | 6.19 | 1.00 | 11.44 | 1.22 |
| numeric | qs (preset = ‘fast’) | 11.85 | 1.47 | 15.79 | 2.55 | 11.49 | 1.22 |
| numeric | CSV via data.table (none) | 28.60 | 3.55 | 16.88 | 2.73 | 24.84 | 2.64 |
| numeric | Parquet (uncompressed) | 47.86 | 5.94 | 28.17 | 4.55 | 12.28 | 1.30 |
| numeric | Parquet + Snappy | 48.46 | 6.01 | 28.77 | 4.65 | 12.28 | 1.31 |
| numeric | Parquet + Zstd | 73.13 | 9.07 | 45.09 | 7.29 | 10.67 | 1.13 |
| numeric | CSV via data.table (gzip) | 270.75 | 33.58 | 440.26 | 71.17 | 10.53 | 1.12 |
| numeric | Parquet + Gzip | 829.00 | 102.82 | 93.75 | 15.16 | 9.41 | 1.00 |
7.2 Throughput plot
# Plot labels
plot_df <- bind_rows(
dplyr::mutate(write_summary_all, phase = "write"),
dplyr::mutate(read_summary_all, phase = "read")
) %>%
dplyr::mutate(method = sub("^(write|read)_", "", expr),
Method = dplyr::recode(method, !!!pretty_method))
unique(plot_df$structure) %>%
walk(~ print(make_structure_plot(.x, log_scale = FALSE)))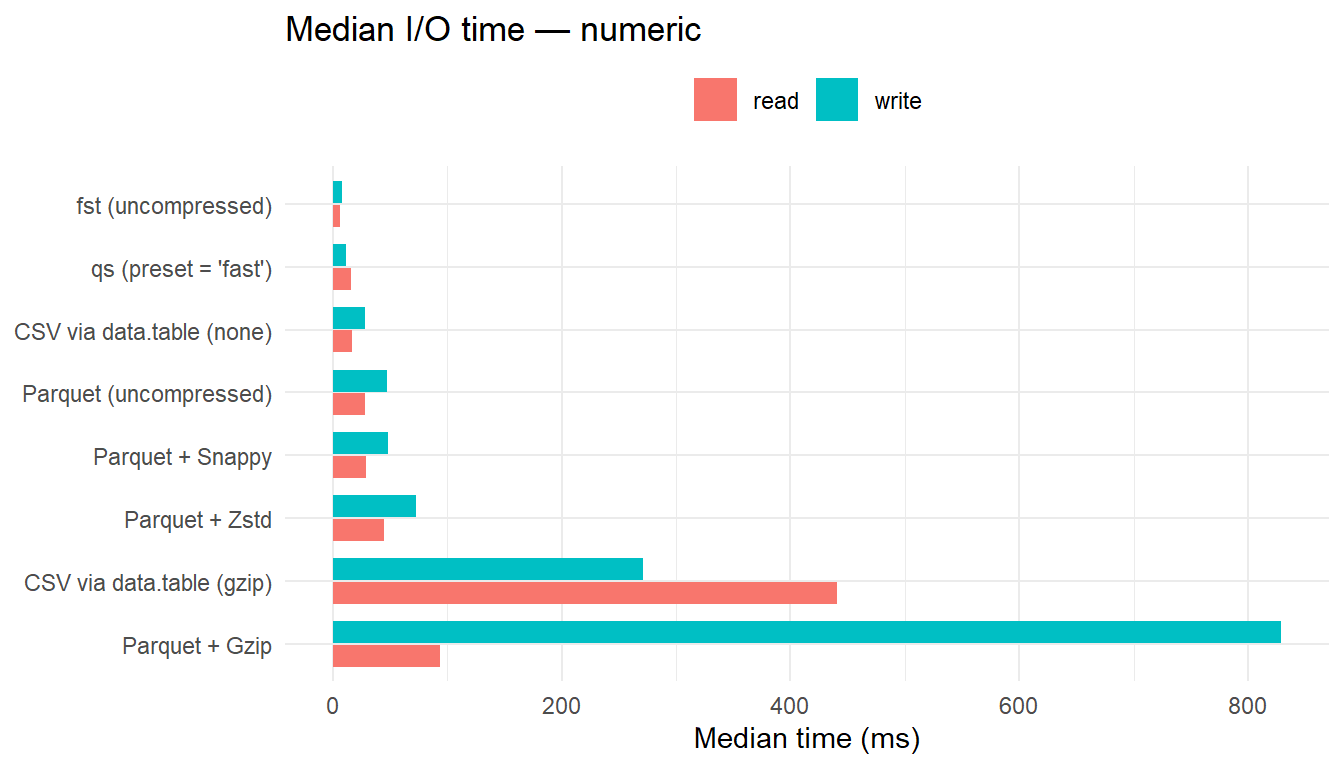
8 Conclusions
8.1 Interpretation
- Write path
- Uncompressed
fstis one of the fastest writer across all structures. qs(preset = "fast") is consistently the next best, offering strong throughput with modest size reduction.data.tableis equivalent tofstin mixed scenario.- Parquet with Gzip is the slowest writer by a large margin in all cases.
- Uncompressed
- Read path
- For numeric data, uncompressed
fstis the fastest reader. - For character and mixed data, Parquet (uncompressed) yields the lowest read latency, with Snappy and Zstd close behind; these formats benefit from reduced on-disk size that offsets decompression overhead.
CSV+Gzipis consistently the slowest reader, particularly for mixed data.
- For numeric data, uncompressed
- File size
- Zstd and Gzip deliver the smallest files across structures.
- Snappy and qs strike a practical balance, with much smaller than uncompressed, and materially better write/read performance than Gzip.
CSVis largest on disk;CSV+Gzipis smaller but slow to read.
- Zstd and Gzip deliver the smallest files across structures.
8.2 Practical perspective
- High-frequency writes should prefer uncompressed
fst(numeric-heavy) orqs(mixed/character) to maximise throughput. - Read-optimised pipelines should prefer Parquet (uncompressed) for minimum latency, or Parquet + Snappy/Zstd when storage reduction matters with minimal read-time penalty.
- Archival or size-constrained storage should favour Parquet + Zstd (or Gzip when maximum compression is required and slower I/O is acceptable).
9 Reproducibility
sessionInfo()## R version 4.4.3 (2025-02-28 ucrt)
## Platform: x86_64-w64-mingw32/x64
## Running under: Windows 11 x64 (build 22631)
##
## Matrix products: default
##
##
## locale:
## [1] LC_COLLATE=English_United Kingdom.utf8
## [2] LC_CTYPE=English_United Kingdom.utf8
## [3] LC_MONETARY=English_United Kingdom.utf8
## [4] LC_NUMERIC=C
## [5] LC_TIME=English_United Kingdom.utf8
##
## time zone: Europe/London
## tzcode source: internal
##
## attached base packages:
## [1] parallel stats graphics grDevices utils datasets methods
## [8] base
##
## other attached packages:
## [1] fstcore_0.9.18 microbenchmark_1.4.10 fst_0.9.8
## [4] qs_0.26.3 arrow_16.1.0 data.table_1.17.8
## [7] lubridate_1.9.3 forcats_1.0.0 stringr_1.5.1
## [10] dplyr_1.1.4 purrr_1.1.0 readr_2.1.5
## [13] tidyr_1.3.1 tibble_3.2.1 ggplot2_3.5.2
## [16] tidyverse_2.0.0
##
## loaded via a namespace (and not attached):
## [1] sass_0.4.9 generics_0.1.4 blogdown_1.21
## [4] stringi_1.8.7 hms_1.1.3 digest_0.6.35
## [7] magrittr_2.0.3 evaluate_1.0.4 grid_4.4.3
## [10] timechange_0.3.0 RColorBrewer_1.1-3 bookdown_0.40
## [13] fastmap_1.2.0 jsonlite_1.8.8 scales_1.4.0
## [16] jquerylib_0.1.4 RApiSerialize_0.1.3 cli_3.6.2
## [19] rlang_1.1.6 bit64_4.6.0-1 withr_3.0.2
## [22] cachem_1.1.0 yaml_2.3.10 tools_4.4.3
## [25] tzdb_0.5.0 assertthat_0.2.1 vctrs_0.6.5
## [28] R6_2.6.1 lifecycle_1.0.4 stringfish_0.16.0
## [31] bit_4.6.0 pkgconfig_2.0.3 RcppParallel_5.1.7
## [34] pillar_1.11.0 bslib_0.7.0 gtable_0.3.6
## [37] Rcpp_1.1.0 glue_1.7.0 xfun_0.52
## [40] tidyselect_1.2.1 rstudioapi_0.17.1 knitr_1.50
## [43] dichromat_2.0-0.1 farver_2.1.2 htmltools_0.5.8.1
## [46] rmarkdown_2.29 compiler_4.4.3Did you find this page helpful? Consider sharing it 🙌
10 How to cite this post
Oliveira, T. de Paula. (2025, March 13). Effects of compression techniques on data read/write performance.
https://prof-thiagooliveira.netlify.app/post/compression-data-read-write-performance/